Week 6 [Feb 18]
💹 Project progress
-
While we allow you to jump straight to AB-4, we recommend you to play around with the AB-3 code base (i.e., fork, clone, setup, and enhance) before moving to AB-4. You can practice with AB-3 while at the the same time updating docs of AB-4 as required by the next project milestone.
-
At this point of the project there are several non-trivial tools you need to learn e.g., JavaFX, Gradle, Travis, Java 8 features, Git, etc. We recommend that you divide up the learning tasks among team members and plan to learn them gradually over the next few weeks.
-
Be reminded that your performance in meeting individual/team project milestones (as detected by our scripts and observed by tutors) will be counted towards your project grade under the project management component. Please do follow exact setup instructions because deviations will affect our script's ability to detect your work.
💰 After reaching 15 participation points:
- We encourage you to continue to do module activities (irrespective of whether they have participation points) because every time you skip a module activity, it can potentially make the remainder of the module a harder for you to follow, due to the highly-connected and iterative nature of this module.
🆘 If you need help
-
Do inform your tutor (or write to the module email) if you are falling behind or cannot cope with the module requirements. While we try to avoid hand holding or spoon feeding students, we do want to help you keep up with the module pace when necessary.
-
If you encounter any technical difficulties when setting up AB-4, please post in our forum so that AB-4 developers can follow up with you. Unlike in first year programming modules, there is no guarantee that tutors will know solutions to your technical problems -- it is not reasonable to even expect so. But you can increase your chances of a solution if you post in the forum as soon as you encounter them. Also, see Admin » Appendix D: Getting Help in this Module
[W6.1] Continuous Integration/Deployment
Can explain integration
Combining parts of a software product to form a whole is called integration. It is also one of the most troublesome tasks and it rarely goes smoothly.
Can explain build automation tools
Build automation tools automate the steps of the build process, usually by means of build scripts.
In a non-trivial project, building a product from source code can be a complex multi-step process. For example, it can include steps such as to pull code from the revision control system, compile, link, run automated tests, automatically update release documents (e.g. build number), package into a distributable, push to repo, deploy to a server, delete temporary files created during building/testing, email developers of the new build, and so on. Furthermore, this build process can be done ‘on demand’, it can be scheduled (e.g. every day at midnight) or it can be triggered by various events (e.g. triggered by a code push to the revision control system).
Some of these build steps such as to compile, link and package are already automated in most modern IDEs. For example, several steps happen automatically when the ‘build’ button of the IDE is clicked. Some IDEs even allow customization to this build process to some extent.
However, most big projects use specialized build tools to automate complex build processes.
Some popular build tools relevant to Java developers:
Some other build tools : Grunt (JavaScript), Rake (Ruby)
Some build tools also serve as dependency management tools. Modern software projects often depend on third party libraries that evolve constantly. That means developers need to download the correct version of the required libraries and update them regularly. Therefore, dependency management is an important part of build automation. Dependency Management tools can automate that aspect of a project.
Maven and Gradle, in addition to managing the build process, can play the role of dependency management tools too.
- Getting Started with Gradle -- Documentation from Gradle
- Gradle Tutorial -- from tutorialspoint.com
Gradle_is used used for,
- a. better revision control
- b. build automation
- c. UML diagramming
- d. project collaboration
(b)
Can explain continuous integration and continuous deployment
An extreme application of build automation is called continuous integration (CI) in which integration, building, and testing happens automatically after each code change.
A natural extension of CI is Continuous Deployment (CD) where the changes are not only integrated continuously, but also deployed to end-users at the same time.
Some examples of CI/CD tools:
- Travis CI for Beginners -- Documentation from Travis
[W6.2] Architecture Diagrams
Can explain what is software design
Design in the creative process of transforming the problem into a solution; the solution is also called design. -- 📖 Software Engineering Theory and Practice, Shari Lawrence; Atlee, Joanne M. Pfleeger
Software design has two main aspects:
- Product/external design: designing the external behavior of the product to meet the users' requirements. This is usually done by product designers with the input from business analysts, user experience experts, user representatives, etc.
- Implementation/internal design: designing how the product will be implemented to meet the required external behavior. This is usually done by software architects and software engineers.
Can interpret an architecture diagram
Architecture diagrams are free-form diagrams. There is no universally adopted standard notation for architecture diagrams. Any symbol that reasonably describes the architecture may be used.
Some example architecture diagrams:



source: https://commons.wikimedia.org
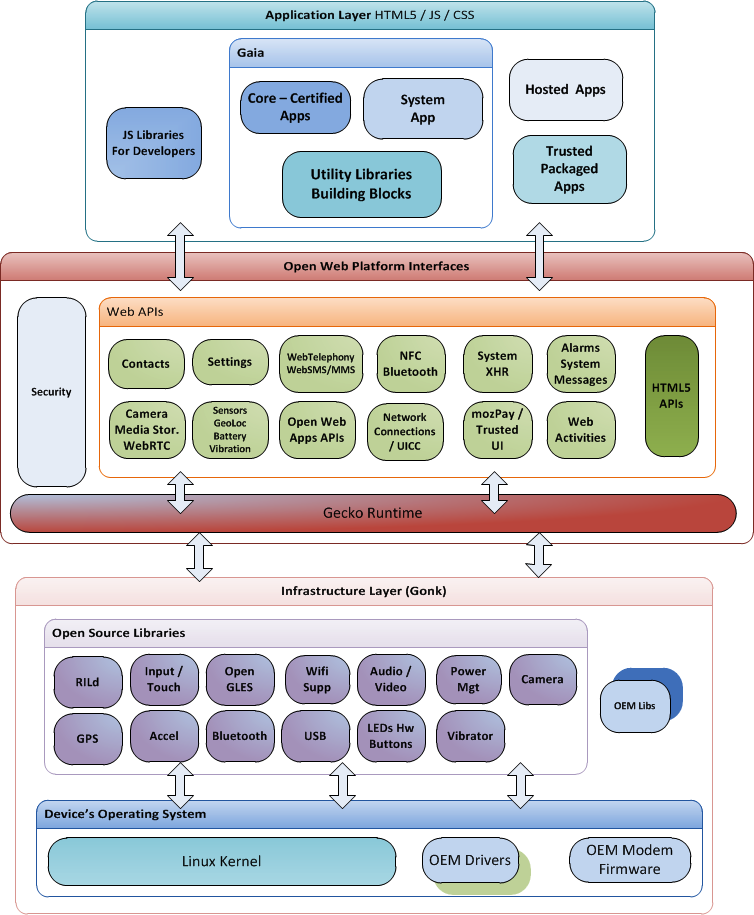
source: https://commons.wikimedia.org

source: https://commons.wikimedia.org
Can explain multi-level design
In a smaller system, design of the entire system can be shown in one place.
This class diagram of se-edu/addressbook-level3 depicts the design of the entire software.

Design of bigger systems needs to be done/shown at multiple levels.
This architecture diagram of se-edu/addressbook-level4 depicts the high-level design of the software.
Here are examples of lower level designs of some components of the same software:
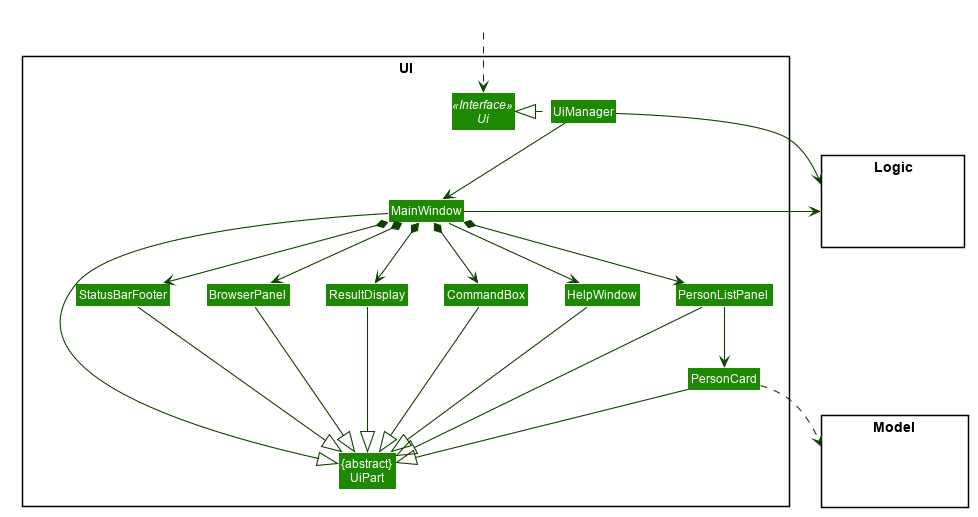
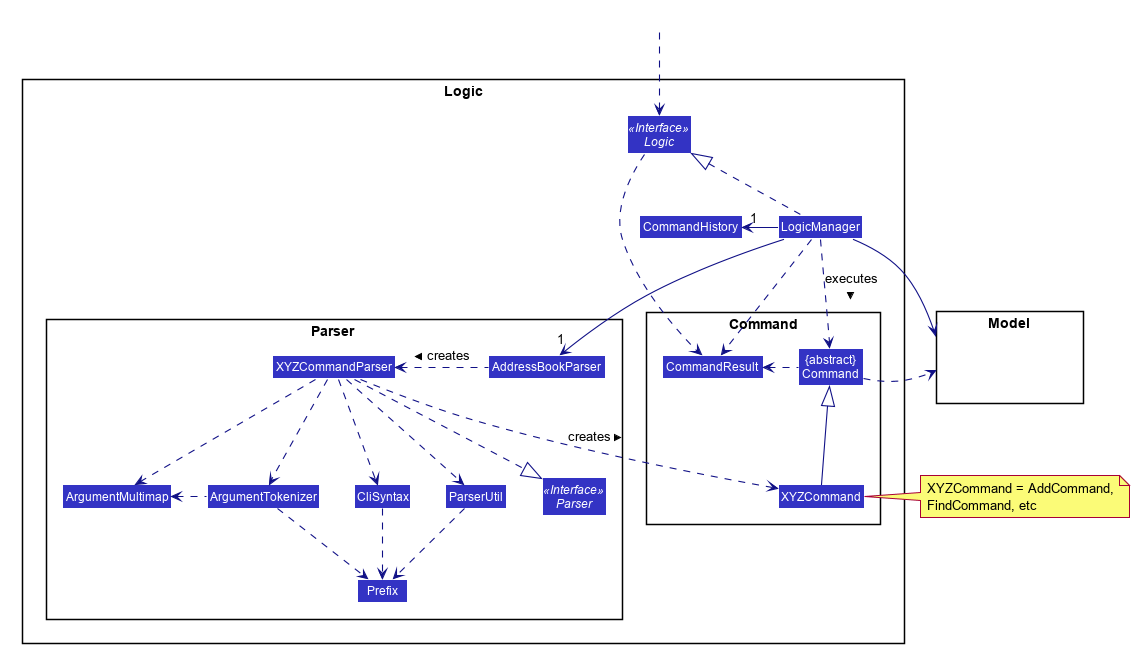
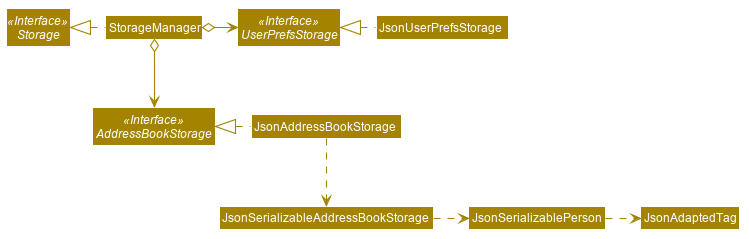
[W6.3] Sequence Diagrams: Basics
Can draw basic sequence diagrams
Explain in your own words the interactions illustrated by this Sequence Diagram:
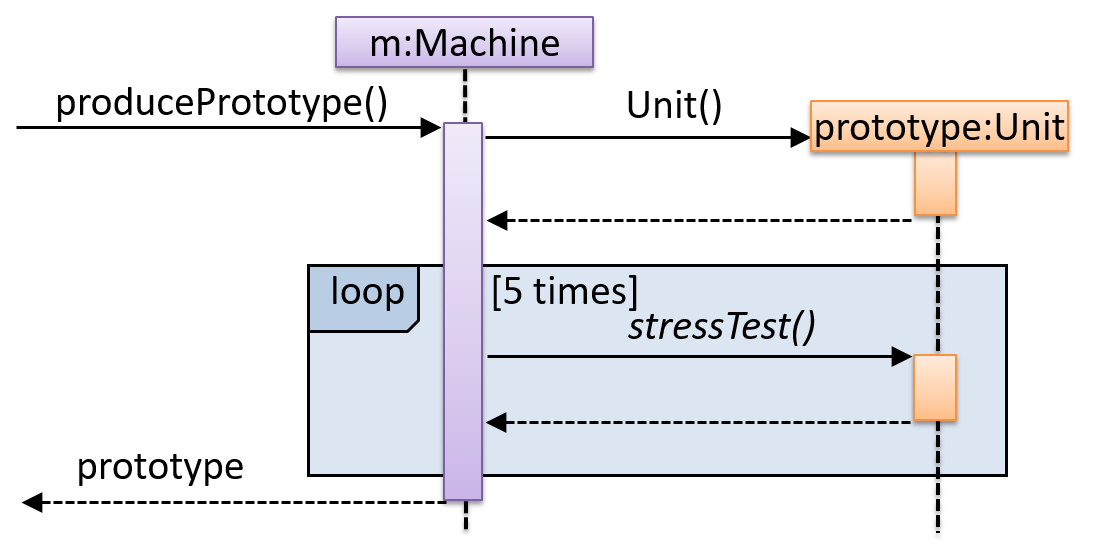
Consider the code below:
class Person{
Tag tag;
String name;
Person(String personName, String tagName){
name = personName;
tag = new Tag(tagName);
}
}
class Tag{
Tag(String value){
//...
}
}
class PersonList{
void addPerson(Person p){
//...
}
}
Draw a sequence diagram to illustrate the object interactions that happen in the code snippet below:
PersonList personList = new PersonList();
while (hasRoom){
Person p = new Person("Adam", "friend");
personList.addPerson(p);
}
Find notation mistakes in the sequence diagram below:
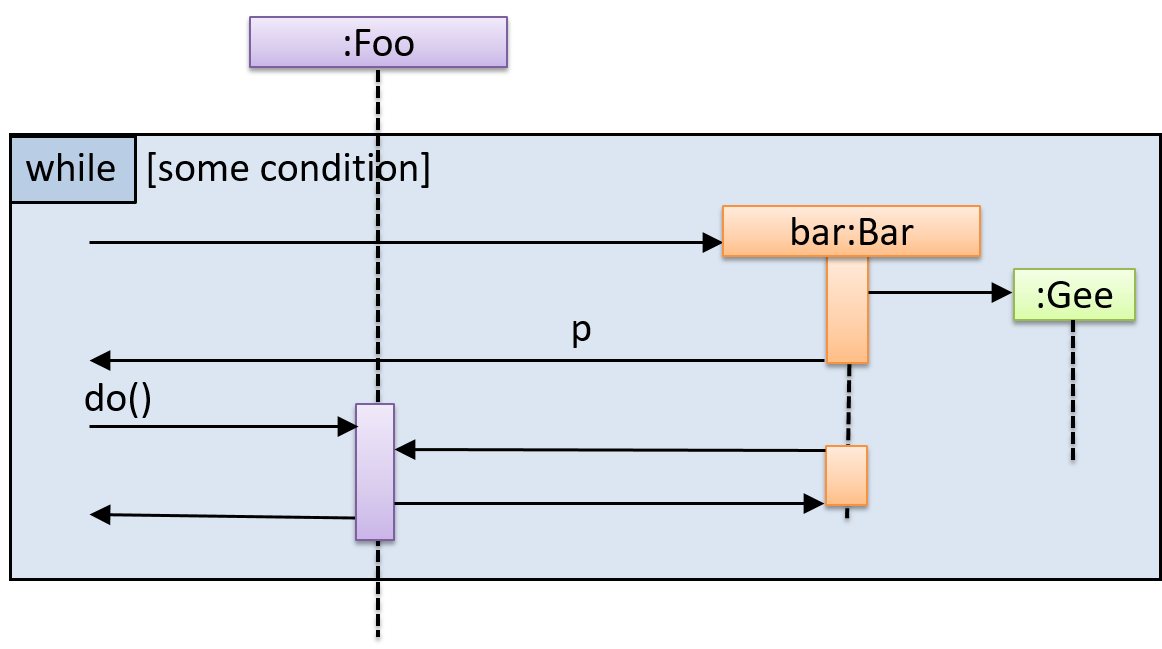
[W6.4] Logging
Can explain logging
Logging is the deliberate recording of certain information during a program execution for future reference. Logs are typically written to a log file but it is also possible to log information in other ways e.g. into a database or a remote server.
Logging can be useful for troubleshooting problems. A good logging system records some system information regularly. When bad things happen to a system e.g. an unanticipated failure, their associated log files may provide indications of what went wrong and action can then be taken to prevent it from happening again.
💡 A log file is like the

{kind=link}
Why is logging like having the 'black box' in an airplane?
(a)
Can use logging
Most programming environments come with logging systems that allow sophisticated forms of logging. They have features such as the ability to enable and disable logging easily or to change the logging
This sample Java code uses Java’s default logging mechanism.
First, import the relevant Java package:
import java.util.logging.*;
Next, create a Logger:
private static Logger logger = Logger.getLogger("Foo");
Now, you can use the Logger object to log information. Note the use of WARNING so that log messages specified as INFO level (which is a lower level than WARNING) will not be written to the log file at all.
// log a message at INFO level
logger.log(Level.INFO, "going to start processing");
//...
processInput();
if(error){
//log a message at WARNING level
logger.log(Level.WARNING, "processing error", ex);
}
//...
logger.log(Level.INFO, "end of processing");
Tutorials:
- Java Logging API - Tutorial -- A tutorial by Lars Vogella
- Java Logging Tutorial -- An alternative tutorial by Jakob Jenkov
- A video tutorial by SimplyCoded:
Best Practices:
- 10 Tips for Proper Application Logging -- by Tomasz Nurkiewicz
- What each logging level means -- conventions recommended by Apache Project
[W6.5] Assertions
Can explain assertions
Assertions are used to define assumptions about the program state so that the runtime can verify them. An assertion failure indicates a possible bug in the code because the code has resulted in a program state that violates an assumption about how the code should behave.
An assertion can be used to express something like when the execution comes to this point, the variable v cannot be null.
If the runtime detects an assertion failure, it typically take some drastic action such as terminating the execution with an error message. This is because an assertion failure indicates a possible bug and the sooner the execution stops, the safer it is.
In the Java code below, suppose we set an assertion that timeout returned by Config.getTimeout() is greater than 0. Now, if the Config.getTimeout() returned -1 in a specific execution of this line, the runtime can detect it as a assertion failure -- i.e. an assumption about the expected behavior of the code turned out to be wrong which could potentially be the result of a bug -- and take some drastic action such as terminating the execution.
int timeout = Config.getTimeout();
Can use assertions
Use the assert keyword to define assertions.
This assertion will fail with the message x should be 0 if x is not 0 at this point.
x = getX();
assert x == 0 : "x should be 0";
...
Assertions can be disabled without modifying the code.
java -enableassertions HelloWorld (or java -ea HelloWorld) will run HelloWorld with assertions enabled while java -disableassertions HelloWorld will run it without verifying assertions.
Java disables assertions by default. This could create a situation where you think all assertions are being verified as true while in fact they are not being verified at all. Therefore, remember to enable assertions when you run the program if you want them to be in effect.
💡 Enable assertions in Intellij (how?) and get an assertion to fail temporarily (e.g. insert an assert false into the code temporarily) to confirm assertions are being verified.
Java assert vs JUnit assertions: They are similar in purpose but JUnit assertions are more powerful and customized for testing. In addition, JUnit assertions are not disabled by default. We recommend you use JUnit assertions in test code and Java assert in functional code.
Tutorials:
- Java Assertions -- a simple tutorial from javatpoint.com
- Programming with Assertions (first half) -- a more detailed tutorial from Oracle
Best practices:
- Programming with Assertions (second half) -- from Oracle (also listed above as a tutorial) contains some best practices towards the end of the article.
Can use assertions optimally
It is recommended that assertions be used liberally in the code. Their impact on performance is considered low and worth the additional safety they provide.
Do not use assertions to do work because assertions can be disabled. If not, your program will stop working when assertions are not enabled.
The code below will not invoke the writeFile() method when assertions are disabled. If that method is performing some work that is necessary for your program, your program will not work correctly when assertions are disabled.
...
assert writeFile() : "File writing is supposed to return true";
Assertions are suitable for verifying assumptions about Internal Invariants, Control-Flow Invariants, Preconditions, Postconditions, and Class Invariants. Refer to [Programming with Assertions (second half)] to learn more.
Exceptions and assertions are two complementary ways of handling errors in software but they serve different purposes. Therefore, both assertions and exceptions should be used in code.
- The raising of an exception indicates an unusual condition created by the user (e.g. user inputs an unacceptable input) or the environment (e.g., a file needed for the program is missing).
- An assertion failure indicates the programmer made a mistake in the code (e.g., a null value is returned from a method that is not supposed to return null under any circumstances).
A Calculator program crashes with an ‘assertion failure’ message when you try to find the square root of a negative number.
(c)
Explanation: An assertion failure indicates a bug in the code. (b) is not acceptable because of the word "terminated". The application should not fail at all for this input. But it could have used an exception to handle the situation internally.
Which statements are correct?
- a. Use assertions to indicate the programmer messed up; Use exceptions to indicate the user or the environment messed up.
- b. Use exceptions to indicate the programmer messed up; Use assertions to indicate the user or the environment messed up.
(a)
[W6.6] Java: JavaFX
Can use JavaFX to build a simple GUI
Adapted (with permissions) from Marco Jakob's JavaFX 8 tutorial.
JavaFx 9 Tutorial - Part 1: Scene Builder
Introduction
This tutorial will teach you how to create a new JavaFX application in IntelliJ, and to use the SceneBuilder to create a layouts for your application.
Prerequisites
- Latest Java JDK 9 (includes JavaFX 9)
- IntelliJ (2018.2 or later)
- SceneBuilder 8 (provided by Gluon as Oracle no longer ships the tool in binary form)
Do remember the installation path to SceneBuilder 8 as we will need it to configure IntelliJ in a later step.
IntelliJ Configurations
If this is the first time using IntelliJ, you need to tell IntelliJ where to find JDK 9 and SceneBuilder.
Configuring JDK 9
- On the Welcome screen, press
Configure→Project Default→Project Structure.

- If you already have a project open, go to the Welcome screen by going to
File→Close Project.
- Under
Project SDK:, pressNew...→JDK. - Select the directory that you install JDK on, and press
OK. - Under
Project language level:, select9 - Modules, private methods in interfaces etc..
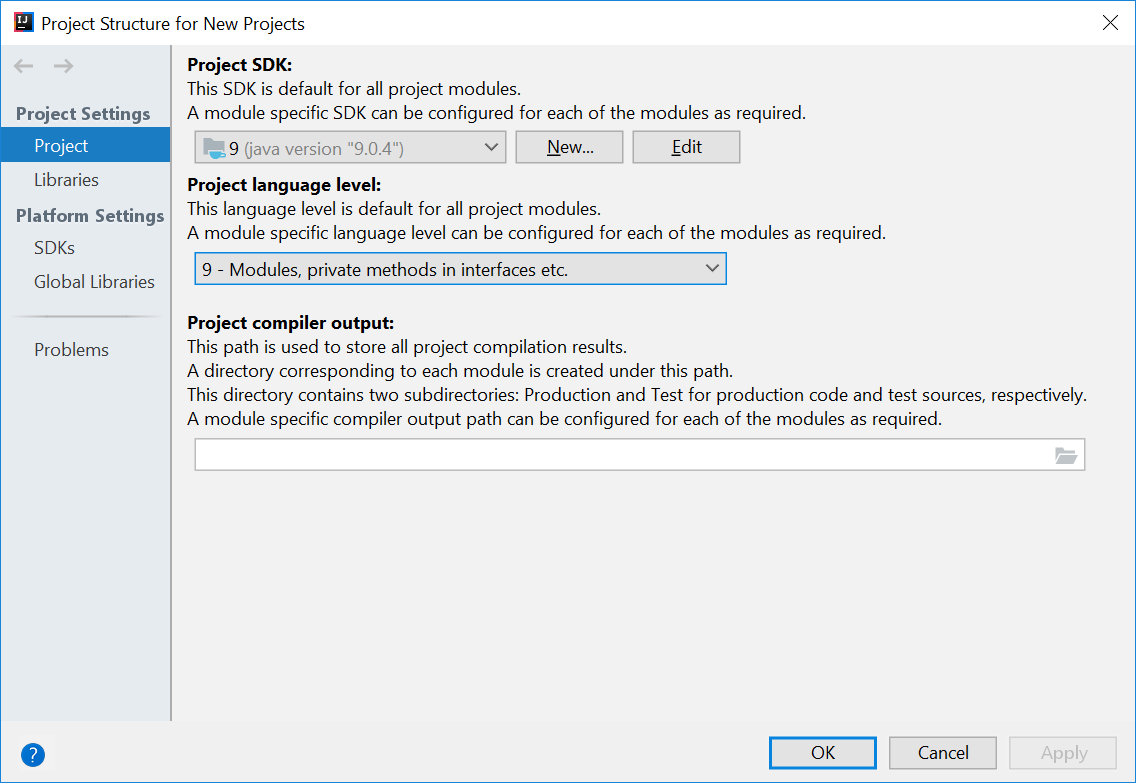
- Press
OKagain.
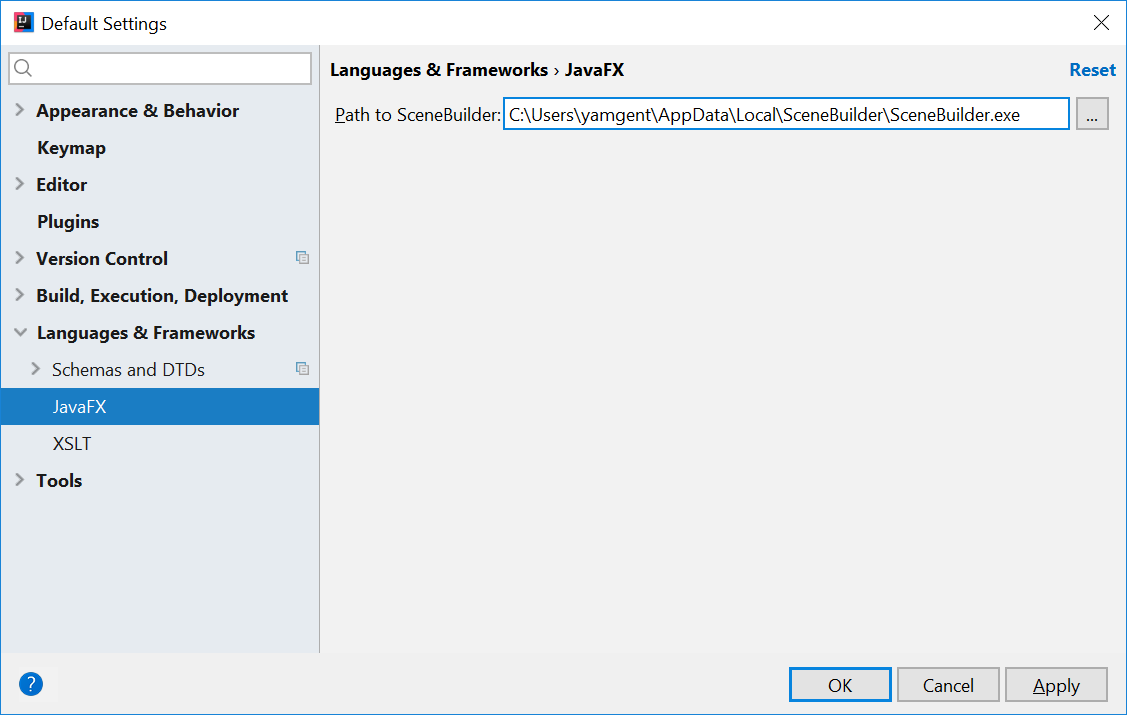
Configuring Scene Builder
- On the Welcome screen, press
Configure→Settings. - On the left hand side, select
Languages & Frameworks→JavaFX - Under
Path to SceneBuilder:, select the path to where SceneBuilder is installed (e.g.C:\Users\Admin\AppData\Local\SceneBuilder\SceneBuilder.exeon Windows)
The JavaDocs will come in handy when writing your own JavaFX applications:
Additionally, Oracle also has a tutorial on JavaFX if you are interested.
Create a new JavaFX Project
- On the Welcome screen, press
Create New Project.
- If you already have a project, you can create a new project by going
File→New→Project....
- On the left side, select
JavaFX. Make sure that the Project SDK is set to9andJavaFX Applicationis selected.
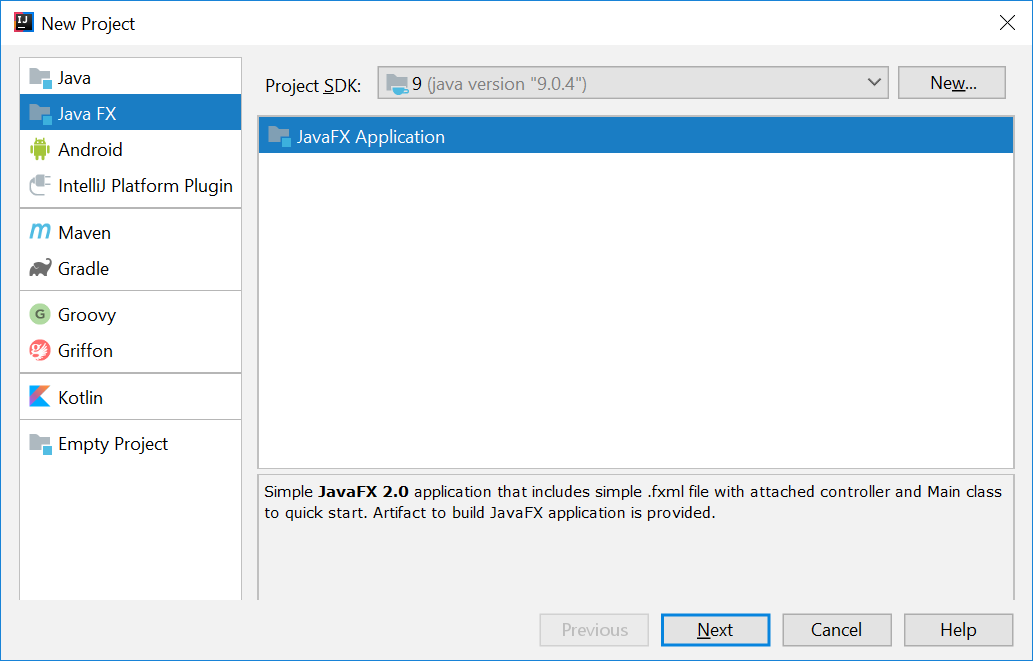
- Press
Next. - Give a name for the application (e.g.
AddressApp), and specify a suitable location. - Press
Finish. If prompted to create a new directory, just pressOK.
Remove the sample package and its content. We will manually create our own package and resources in our tutorial.
We will also have to set up the IDE further, so that warnings and errors show up correctly when working with Java 9:
- Go to the menu
File→Project Structure. - Under
Project language level:, ensure that9 - Modules, private methods in interfaces etc.is selected.
Create the Packages
In We will create a package for each of the component. Ensure that your Project pane is open (Alt+1). Right click on the src folder, and select New → Package:
seedu.address- contains the controller classes (i.e. the part that deals with the business logic)seedu.address.model- contains the model classes (i.e. the part that deals with data)seedu.address.view- contains the views (i.e. the part that deals with presenting the data to the user)
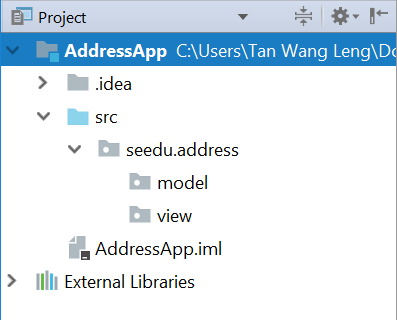
In subsequent tutorials, our view package will also contain some controllers that are directly related to a single view. We will call them view-controllers.
Create the FXML Layout File
There are two ways to create the UI:
- Use FXML, which is an XML format.
- Programmatically create the interface in Java.
We will use FXML for most parts, so that we can separate the view and controller from each other. Furthermore, we are able to use the Scene Builder tool to edit our FXML file. That means we will not have to directly work with XML.
Right click on the view package, and press New → FXML file. For the file name, type PersonOverview.fxml.
Design with Scene Builder
Right-click on PersonOverview.fxml and choose Open with Scene Builder. Now you should see the Scene Builder with just an AnchorPane (visible under Hierarchy on the left).
If IntelliJ prompts for a location of the SceneBuilder executable, make sure to point to where you install SceneBuilder.
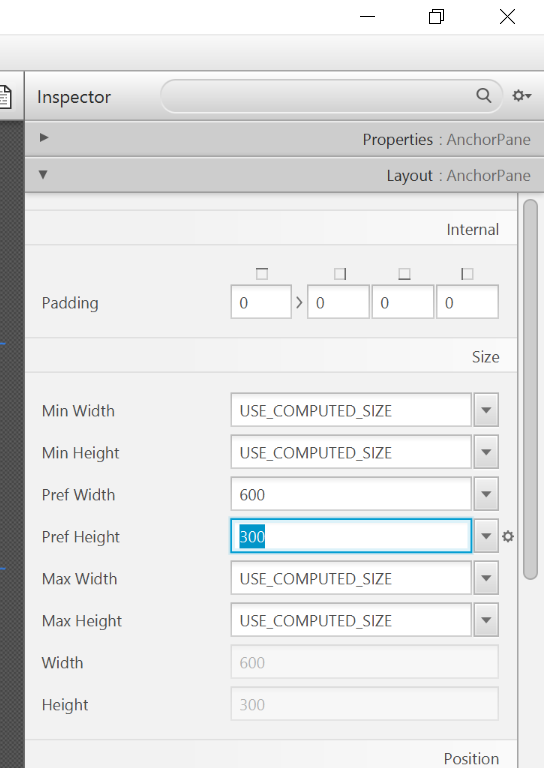
- Select the
Anchor Panein your Hierarchy, and adjust the size under Layout (right side). (Pref Width: 600, Pref Height: 300)
- Add a
Split Pane (horizontal)(underContainers) by dragging it from the Library into the main area. Right-click theSplit Panein the Hierarchy view and selectFit to Parent.
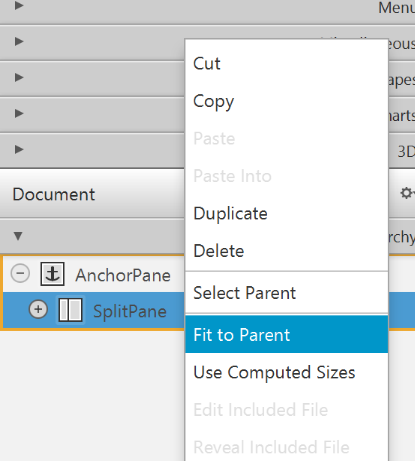
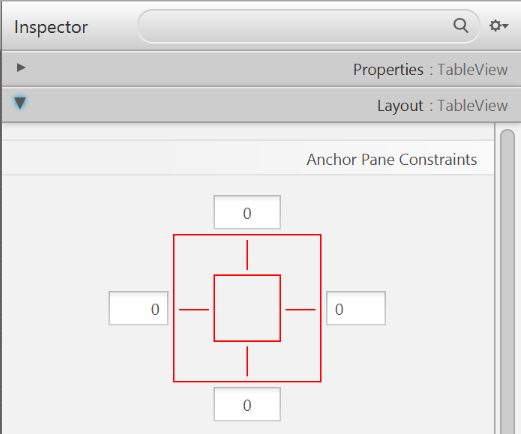
- Drag a
TableView(underControlsin Library view) into the left side of theSplitPane. Select theTableView(not a Column) and set the following layout constraints in the Inspector to theTableView. Inside anAnchorPaneyou can always set anchors to the four borders (see this page for more information on Layouts).
-
Go to the menu
Preview→Show Preview in Windowto see whether the layout configuration is done correctly. Try resizing the window. TheTableViewshould resize together with the window as it is anchored to the borders. -
Change the column text (under Properties) to "First Name" and "Last Name".
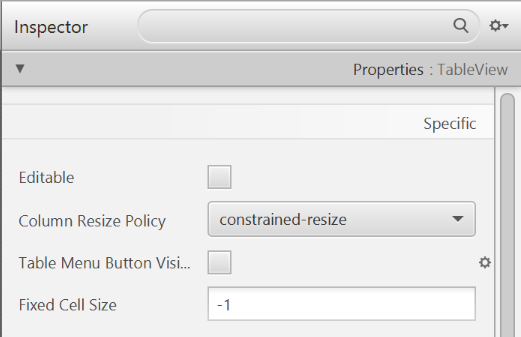
- Select the
TableViewand chooseconstrainted-resizefor the 'Column Resize Policy'. This ensures that the columns will always fill up the entire available space.
- Add a
Labelon the right side with the text "Person Details:". Adjust the layout using anchors (Top: 5, Left: 5. Right: Blank, Bottom: Blank).

You can use the Search Bar at the top of Library/Inspector to find the respective controls/properties.
- Add a
GridPaneon the right side. Select it, and adjust its layout using anchors (Top: 30, Left: 5, Right: 5, Bottom: Blank).
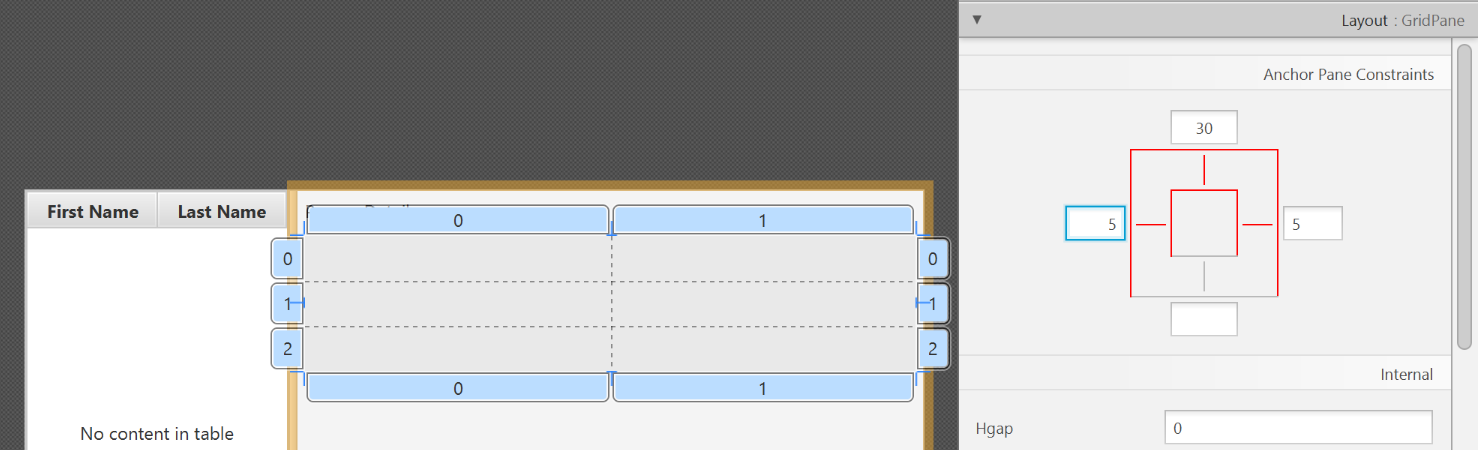
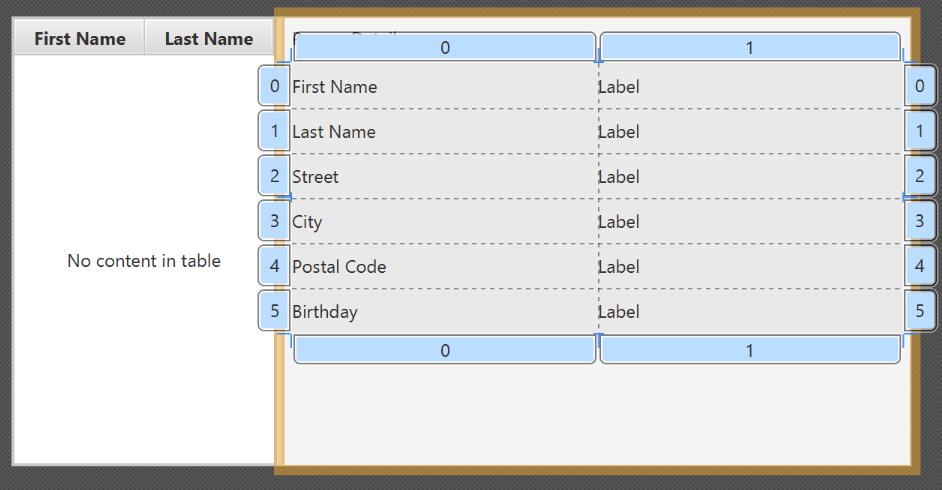
- Add the following labels to the cells, such that the grid is of this form:
| First Name | Label |
|---|---|
| Last Name | Label |
| Street | Label |
| City | Label |
| Postal Code | Label |
| Birthday | Label |
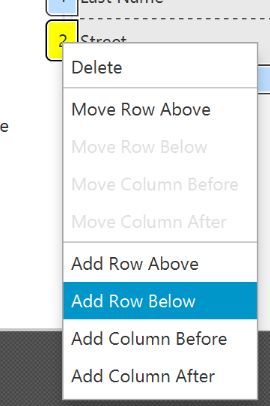
To add a row to the GridPane, select an existing row number, right click the row number and choose "Add Row Below".
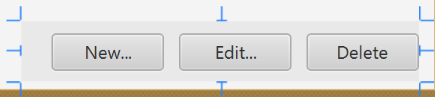
- Add a
ButtonBarat the bottom. Add three buttons to the bar ("New...", "Edit...","Delete"). Adjust the anchors so that it stays at the bottom right (Top: Blank, Left: Blank, Right: 10, Bottom: 5).
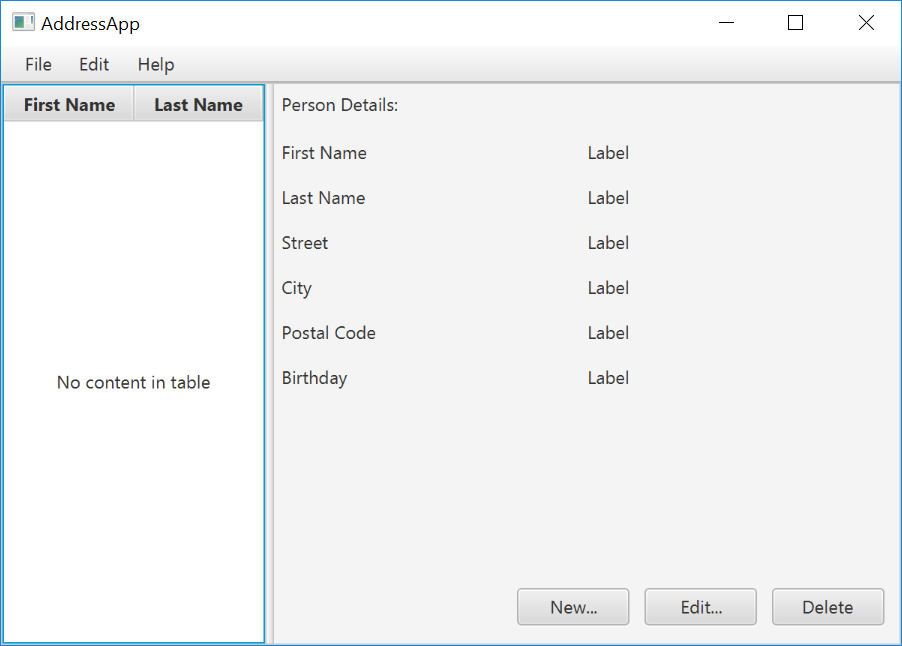
- Now you should see something like the following. Use the
Previewmenu to test its resizing behaviour.
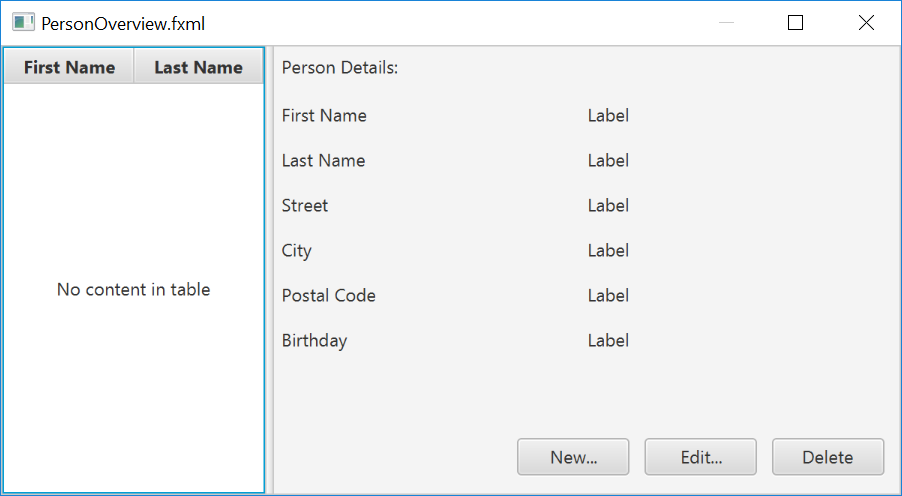
- Save the
.fxmlfile.
Create the Main Application
The PersonOverview.fxml that we just created only contains the content of our entire application. We need another FXML for our root layout, which will contain a menu bar and wraps PersonOverview.fxml.
- Inside IntelliJ, right click on the
viewpackage, and pressNew→FXML file. For the file name, typeRootLayout.fxml. - Right-click on
RootLayout.fxmland chooseOpen with Scene Builder. - Delete the
AnchorPane. We will use another pane for our root layout.
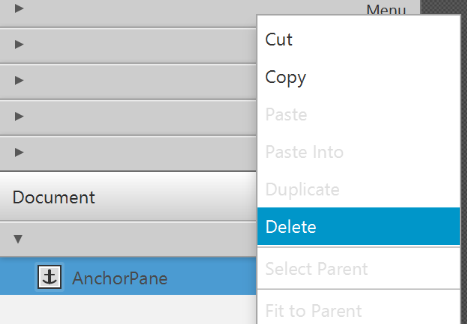
- Add
BorderPaneby dragging it from the Library view into the main area.
- Resize the
BorderPane(Pref Width: 600, Pref Height: 400)
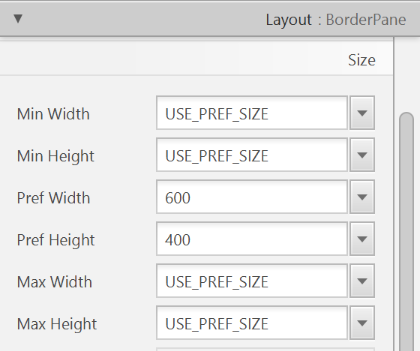
- Add a
MenuBarinto theinsert TOPslot. We will not implement menu functionality for now.

The JavaFX Main Class
Now, we need to create the main Java class that starts up our application with the RootLayout.fxml and adds the PersonOverview.fxml in the center.
Right-click on your seedu.address package, and choose New → JavaFXApplication. For the class name, type MainApp.
The generated MainApp.java class extends from Application and contains two methods. This is the basic structure that we need to start a JavaFX Application. The most important part for us is the start(Stage primaryStage) method. It is automatically called when the application is launch() from within the main() method.
As you see, the start(...) method receives a Stage as parameter. The following graphic illustrates the structure of every JavaFX application:
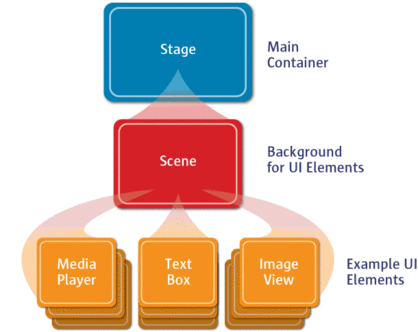
Image Source: http://www.oracle.com
It's like a theater play: The Stage is the main container which is usually a Window with a border and the typical minimize, maximize and close buttons. Inside the Stage you add a Scene which can, of course, be switched out by another Scene. Inside the Scene the actual JavaFX nodes like AnchorPane, TextBox, etc. are added.
See this page for more info on working with the JavaFX Scene Graph.
Open MainApp.java and replace the code with the following:
MainApp.java
package seedu.address;
import java.io.IOException;
import javafx.application.Application;
import javafx.fxml.FXMLLoader;
import javafx.scene.Scene;
import javafx.scene.layout.AnchorPane;
import javafx.scene.layout.BorderPane;
import javafx.stage.Stage;
public class MainApp extends Application {
private Stage primaryStage;
private BorderPane rootLayout;
@Override
public void start(Stage primaryStage) {
this.primaryStage = primaryStage;
this.primaryStage.setTitle("AddressApp");
initRootLayout();
showPersonOverview();
}
/**
* Initializes the root layout.
*/
public void initRootLayout() {
try {
// Load root layout from fxml file.
FXMLLoader loader = new FXMLLoader();
loader.setLocation(MainApp.class.getResource("view/RootLayout.fxml"));
rootLayout = loader.load();
// Show the scene containing the root layout.
Scene scene = new Scene(rootLayout);
primaryStage.setScene(scene);
primaryStage.show();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* Shows the person overview inside the root layout.
*/
public void showPersonOverview() {
try {
// Load person overview.
FXMLLoader loader = new FXMLLoader();
loader.setLocation(MainApp.class.getResource("view/PersonOverview.fxml"));
AnchorPane personOverview = loader.load();
// Set person overview into the center of root layout.
rootLayout.setCenter(personOverview);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* Returns the main stage.
*/
public Stage getPrimaryStage() {
return primaryStage;
}
public static void main(String[] args) {
launch(args);
}
}
The various comments should give you some hints about what's going on.
Importing JavaFx 9
JavaFx 9 is a separate module from Java 9. We must ensure that the modules are imported correctly.
Notice that IntellJ will complain about the imported modules "not being in the module graph":
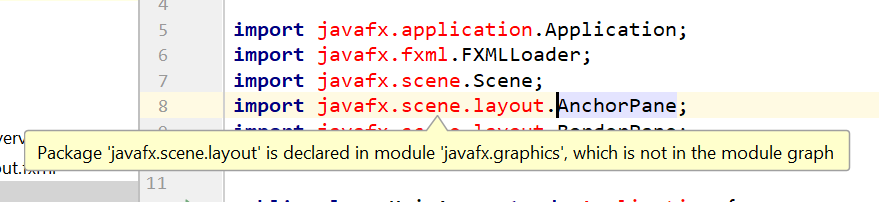
To fix this:
- Ensure that your Project pane is open (Alt+1). Right click on the
srcfolder, and selectNew→module-info.java: - Add the following
requiresandexportsin order to import and export the modules correctly:
module AddressApp {
requires javafx.graphics;
requires javafx.fxml;
requires javafx.controls;
exports seedu.address;
}
Running the Application
If you run the application now (right click MainApp.java and select Run MainApp.main()), you should see something like this:
Possible Issues
If JavaFx fails to load PersonOverview.fxml, you might get the following error message:
javafx.fxml.LoadException:
/.../AddressApp/out/production/AddressApp/seedu/address/view/PersonOverview.fxml:15
To solve this issue, open PersonOverview.fxml normally in IntelliJ and ensure that there is no such attribute around:
fx:controller="seedu.address.view.PersonOverview"
JavaFx 9 tutorial - Part 2: Model and TableView
Introduction
In this tutorial, we will create the other parts of the application (mainly the model and the controller). We will also use ObservableList and *Property to bind our list of new model's Persons, and their individual details, to the view, with the controller as the "middleman".
Create the Model class
We need a model class in order to hold information about the people in our address book. Add a new class to the model package (seedu.address.model) called Person. The Person class will encapsulate the details of an individual person such as name, address and birthday. Add the following code to the class. The JavaFX specifics will be explained after the code snippet.
Person.java
package seedu.address.model;
import java.time.LocalDate;
import javafx.beans.property.IntegerProperty;
import javafx.beans.property.ObjectProperty;
import javafx.beans.property.SimpleIntegerProperty;
import javafx.beans.property.SimpleObjectProperty;
import javafx.beans.property.SimpleStringProperty;
import javafx.beans.property.StringProperty;
/**
* Model class for a Person.
*/
public class Person {
private final StringProperty firstName;
private final StringProperty lastName;
private final StringProperty street;
private final IntegerProperty postalCode;
private final StringProperty city;
private final ObjectProperty< LocalDate > birthday;
/**
* Default constructor.
*/
public Person() {
this(null, null);
}
/**
* Constructor with some initial data.
*/
public Person(String firstName, String lastName) {
this.firstName = new SimpleStringProperty(firstName);
this.lastName = new SimpleStringProperty(lastName);
// Some initial dummy data, just for convenient testing.
this.street = new SimpleStringProperty("some street");
this.postalCode = new SimpleIntegerProperty(1234);
this.city = new SimpleStringProperty("some city");
this.birthday = new SimpleObjectProperty< LocalDate >(LocalDate.of(1999, 2, 21));
}
public String getFirstName() {
return firstName.get();
}
public void setFirstName(String firstName) {
this.firstName.set(firstName);
}
public StringProperty firstNameProperty() {
return firstName;
}
public String getLastName() {
return lastName.get();
}
public void setLastName(String lastName) {
this.lastName.set(lastName);
}
public StringProperty lastNameProperty() {
return lastName;
}
public String getStreet() {
return street.get();
}
public void setStreet(String street) {
this.street.set(street);
}
public StringProperty streetProperty() {
return street;
}
public int getPostalCode() {
return postalCode.get();
}
public void setPostalCode(int postalCode) {
this.postalCode.set(postalCode);
}
public IntegerProperty postalCodeProperty() {
return postalCode;
}
public String getCity() {
return city.get();
}
public void setCity(String city) {
this.city.set(city);
}
public StringProperty cityProperty() {
return city;
}
public LocalDate getBirthday() {
return birthday.get();
}
public void setBirthday(LocalDate birthday) {
this.birthday.set(birthday);
}
public ObjectProperty< LocalDate > birthdayProperty() {
return birthday;
}
}
Explanations
- With JavaFX, it is common to use
*Propertyfor all fields of a model class. APropertyallows us, for example, to automatically be notified when thelastNameor any other variable is changed. This helps us keep the view in sync with the data. - To learn more about
*Property, refer to Using JavaFX Properties and Binding LocalDate, the type that we are using forbirthday, is part of the new Date and Time API since JDK 8
A List of Persons
The main data that our application manages is simply a bunch of persons. Let's create a list of Person objects inside the MainApp class. All other controller classes will later get access to that central list inside the MainApp.
ObservableList
We are working with JavaFX view classes that need to be informed about any changes made to the list of persons. This is important, since otherwise the view would not be in sync with the data. For this purpose, JavaFX introduces some new Collection classes.
Among all these collections, we need the ObservableList. To create a new ObservableList, add the following code at the beginning of the MainApp class. We'll also add a constructor that creates some sample data and a public getter method:
MainApp.java
// ... AFTER THE OTHER VARIABLES ...
/**
* The data as an observable list of {@link Person}.
*/
private ObservableList< Person > personData = FXCollections.observableArrayList();
/**
* Constructor
*/
public MainApp() {
// Add some sample data
personData.add(new Person("Hans", "Muster"));
personData.add(new Person("Ruth", "Mueller"));
personData.add(new Person("Heinz", "Kurz"));
personData.add(new Person("Cornelia", "Meier"));
personData.add(new Person("Werner", "Meyer"));
personData.add(new Person("Lydia", "Kunz"));
personData.add(new Person("Anna", "Best"));
personData.add(new Person("Stefan", "Meier"));
personData.add(new Person("Martin", "Mueller"));
}
/**
* Returns the data as an observable list of {@link Person}.
*/
public ObservableList< Person > getPersonData() {
return personData;
}
// ... THE REST OF THE CLASS ...
The PersonOverviewController
We have our model and view. Let's get our data into our table. We'll need a controller for our PersonOverview.fxml to act as a "middleman" for the model and view.
Create a normal Java class inside the view package called PersonOverviewController.
Note: We must put the class inside the same package as PersonOverview.fxml, otherwise the SceneBuilder won't be able to find it.
We will add some instance variables that give us access to the table and the labels inside the view. The fields and some methods have a special @FXML annotation. This is necessary in order for the .fxml file to have access to private fields and private methods. After we have everything set up in the .fxml file, the application will automatically fill the variables when the .fxml file is loaded.
So let's add the following code:
Note: Remember to always use the javafx imports, NOT awt or swing.
PersonOverviewController.java
package seedu.address.view;
import javafx.fxml.FXML;
import javafx.scene.control.Label;
import javafx.scene.control.TableColumn;
import javafx.scene.control.TableView;
import seedu.address.MainApp;
import seedu.address.model.Person;
public class PersonOverviewController {
@FXML
private TableView< Person> personTable;
@FXML
private TableColumn< Person, String> firstNameColumn;
@FXML
private TableColumn< Person, String> lastNameColumn;
@FXML
private Label firstNameLabel;
@FXML
private Label lastNameLabel;
@FXML
private Label streetLabel;
@FXML
private Label postalCodeLabel;
@FXML
private Label cityLabel;
@FXML
private Label birthdayLabel;
// Reference to the main application.
private MainApp mainApp;
/**
* The constructor. It is called before the initialize() method.
*/
public PersonOverviewController() {
}
/**
* Initializes the controller class. This method is automatically called
* after the fxml file has been loaded.
*/
@FXML
private void initialize() {
// Initialize the person table with the two columns.
firstNameColumn.setCellValueFactory(cellData -> cellData.getValue().firstNameProperty());
lastNameColumn.setCellValueFactory(cellData -> cellData.getValue().lastNameProperty());
}
/**
* Is called by the main application to give a reference back to itself.
*/
public void setMainApp(MainApp mainApp) {
this.mainApp = mainApp;
// Add observable list data to the table
personTable.setItems(mainApp.getPersonData());
}
}
Explanations
- All fields and methods where the
.fxmlfile needs access must be annotated with@FXML.- Actually, only if they are private, but it's better to have them private and mark them with the annotation!
- The
initialize()method is automatically called after the.fxmlfile has been loaded. At this time, all the FXML fields should have been initialized already. - The
setCellValueFactory(...)that we set on the table colums are used to determine which field inside thePersonobjects should be used for the particular column. The arrow->indicates that we're using a Java 8 feature called Lambdas. (Another option would be to use aPropertyValueFactory, but this is not type-safe).
Note:
We're only using StringProperty values for our table columns in this example. When you want to use IntegerProperty or DoubleProperty, the setCellValueFactory(...) must have an additional asObject():
myIntegerColumn.setCellValueFactory(cellData ->
cellData.getValue().myIntegerProperty().asObject());
This is necessary because of a bad design decision of JavaFX (see this discussion for more details).
Connecting MainApp with the PersonOverviewController
The setMainApp(...) method must be called by the MainApp class. This gives us a way to access the MainApp object and get the list of Persons and other things. Add the following three lines to showPersonOverview() the method:
MainApp.java - additional lines to add to showPersonOverview() method
// (.... root layout statement goes here ....)
// Give the controller access to the main app.
PersonOverviewController controller = loader.getController();
controller.setMainApp(this);
// (.... catch statement goes here ....)
Your showPersonOverview() method in MainApp should now look like this:
MainApp.java - new showPersonOverview() method
/**
* Shows the person overview inside the root layout.
*/
public void showPersonOverview() {
try {
// Load person overview.
FXMLLoader loader = new FXMLLoader();
loader.setLocation(MainApp.class.getResource("view/PersonOverview.fxml"));
AnchorPane personOverview = loader.load();
// Set person overview into the center of root layout.
rootLayout.setCenter(personOverview);
// Give the controller access to the main app.
PersonOverviewController controller = loader.getController();
controller.setMainApp(this);
} catch (IOException e) {
e.printStackTrace();
}
}
Hook the View to the controller
We're almost there! But one thing is missing: We haven't told our PersonOverview.fxml file which controller to use, and which element should match to which field inside the controller.
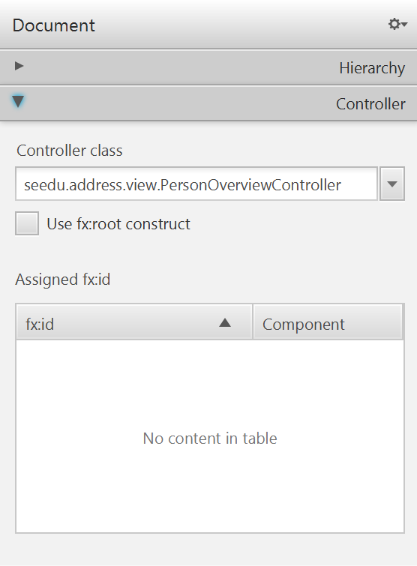
- Open
PersonOverview.fxmlwith the SceneBuilder. - Open the Controller group on the left side (just below Hierarchy), and select the
seedu.address.view.PersonOverviewControlleras the controller class.
- Select the
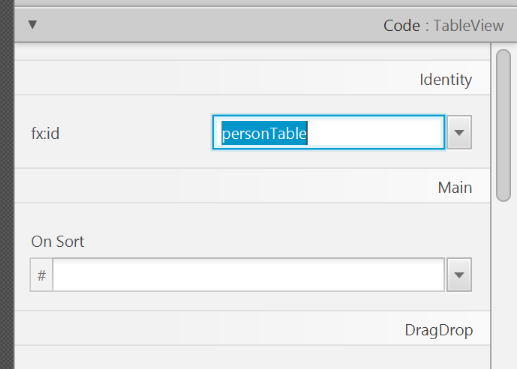
TableViewin the Hierarchy group. - In the Inspector view, under the Code group, set 'fx:id' to
personTable.
- Do the same for the table columns. Select
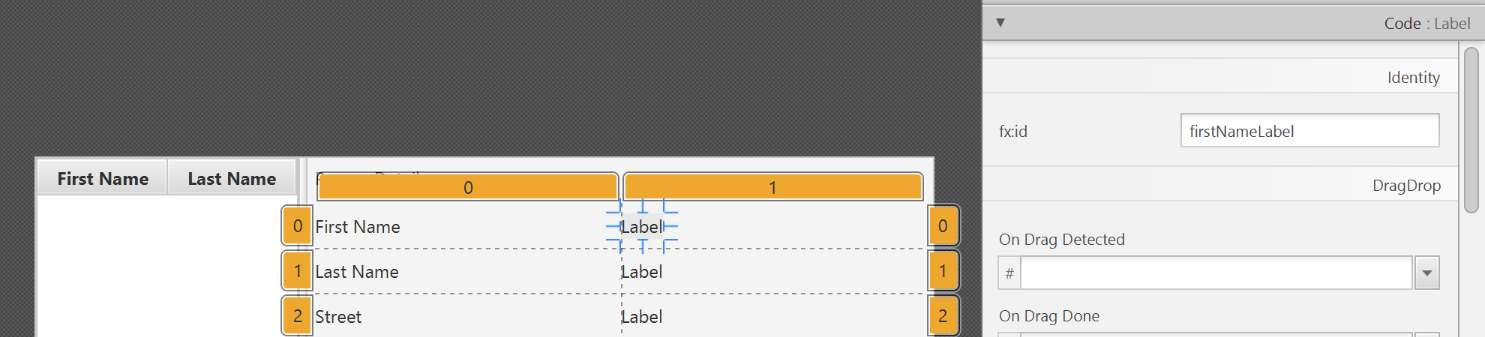
firstNameColumnandlastNameColumnfor the 'fx:id' respectively. - For each label in the second column of the grid pane, choose the corresponding 'fx:id'.
- Save the
.fxmlfile.
Opening up the PersonOverviewController to JavaFx
If you try and run the application now, you will encounter the following error:
javafx.fxml.LoadException: ...
...
Caused by: java.lang.IllegalAccessException: class javafx.fxml.FXMLLoader$ValueElement (in module javafx.fxml) cannot access class seedu.address.view.PersonOverviewController (in module AddressApp) because module AddressApp does not export seedu.address.view to module javafx.fxml
This is because JavaFx is unable to access our PersonOverviewController class.
To fix this, add this line of code to src/module-info.java:
module AddressApp {
...
opens seedu.address.view;
}
The file should now look something like this:
module-info.java
module AddressApp {
requires javafx.graphics;
requires javafx.fxml;
requires javafx.controls;
exports seedu.address;
opens seedu.address.view;
}
Start the Application
When you start your application now, you should see something like this:
Congratulations! The application now shows the list of Persons in the view!
You may notice that selecting a person in the TableView does nothing to the labels at the right side. That is because the user interaction portion has not been programmed yet, which we will cover in the next part of the tutorial.
[W6.7] Java: streams
Can use Java8 streams
Java 8 introduced a number of new features (e.g. Lambdas, Streams) that are not trivial to learn but also extremely useful to know.
Here is an overview of new Java 8 features . (written by Benjamin Winterberg)
Tutorials:
- Java 8 Tutorial -- from tutorialspoint.com. 💡 Also provides a way to try out code online
- Tutorials from Oracle: [Lambdas][Streams]
A video tutorial by well-known Java coach Venkat Subramaniam
Project Preparation: 3 KLoC
[Optional, but recommended] If you are not comfortable jumping from AB-2 (~2KLoc) straight to AB-4 (~10KLoc), we recommend that you play around with [AddressBook - Level3] for a bit before moving to AB-4. As before, fork, clone, set up project in your Computer, and try to do a small enhancement to AB-3.
How AB-3 differs from AB-2:
- A simple GUI has been added to replace the Text UI.
- No more I/O tests
- A
Logicclass has been added together with aLogicTestclass.
Project Milestone: mid-v1.1
Set up project repo, start moving UG and DG to the repo, attempt to do local-impact changes to the code base.
Project Management:
Set up the team org and the team repo as explained below:
Relevant: [
Organization setup
Please follow the organization/repo name format precisely because we use scripts to download your code or else our scripts will not be able to detect your work.
After receiving your team ID, one team member should do the following steps:
- Create a GitHub organization with the following details:
- Organization name :
CS2103-AY1819S2-TEAM_ID. e.g.CS2103-AY1819S2-W12-1 - Plan: Open Source ($0/month)
- Organization name :
- Add members to the organization:
- Create a team called
developersto your organization. - Add your team members to the developers team.
- Create a team called
Relevant: [
Repo setup
Only one team member:
- Fork Address Book Level 4 to your team org.
- Rename the forked repo as
main. This repo (let's call it the team repo) is to be used as the repo for your project. - Ensure the issue tracker of your team repo is enabled. Reason: our bots will be posting your weekly progress reports on the issue tracker of your team repo.
- Ensure your team members have the desired level of access to your team repo.
- Enable Travis CI for the team repo.
- Set up auto-publishing of docs. When set up correctly, your project website should be available via the URL
https://cs2103-ay1819s2-{team-id}.github.io/maine.g.,https://cs2103-ay1819s2-w13-1.github.io/main/. This also requires you to enable the GitHub Pages feature of your team repo and configure it to serve the website from thegh-pagesbranch. - Create a team PR for us to track your project progress: i.e., create a PR from your team repo
masterbranch to [nus-cs2103-AY1819S2/addressbook-level4]masterbranch. PR name:[Team ID] Product Namee.g.,[T09-2] Contact List Pro. As you merge code to your team repo'smasterbranch, this PR will auto-update to reflect how much your team's product has progressed. In the PR description@mention the other team members so that they get notified when the tutor adds comments to the PR.
All team members:
- Watch the
mainrepo (created above) i.e., go to the repo and click on thewatchbutton to subscribe to activities of the repo - Fork the
mainrepo to your personal GitHub account. - Clone the fork to your Computer.
- Recommended: Set it up as an Intellij project (follow the instructions in the Developer Guide carefully).
- Set up the developer environment in your computer. You are recommended to use JDK 9 for AB-4 as some of the libraries used in AB-4 have not updated to support Java 10 yet. JDK 9 can be downloaded from the Java Archive.
Note that some of our download scripts depend on the following folder paths. Please do not alter those paths in your project.
/src/main/src/test/docs
When updating code in the repo, follow the workflow explained below:
Relevant: [
Workflow
Before you do any coding for the project,
- Ensure you have
set the Git username correctly (as explained in Appendix E) in all Computers you use for coding. - Read
our reuse policy (in Admin: Appendix B) , in particular, how to give credit when you reuse code from the Internet or classmates:
Setting Git Username to Match GitHub Username
We use various tools to analyze your code. For us to be able to identify your commits, you should use the GitHub username as your Git username as well. If there is a mismatch, or if you use multiple user names for Git, our tools might miss some of your work and as a result you might not get credit for some of your work.
In each Computer you use for coding, after installing Git, you should set the Git username as follows.
- Open a command window that can run Git commands (e.g., Git bash window)
- Run the command
git config --global user.name YOUR_GITHUB_USERNAME
e.g.,git config --global user.name JohnDoe
More info about setting Git username is here.
Policy on reuse
Reuse is encouraged. However, note that reuse has its own costs (such as the learning curve, additional complexity, usage restrictions, and unknown bugs). Furthermore, you will not be given credit for work done by others. Rather, you will be given credit for using work done by others.
- You are allowed to reuse work from your classmates, subject to following conditions:
- The work has been published by us or the authors.
- You clearly give credit to the original author(s).
- You are allowed to reuse work from external sources, subject to following conditions:
- The work comes from a source of 'good standing' (such as an established open source project). This means you cannot reuse code written by an outside 'friend'.
- You clearly give credit to the original author. Acknowledge use of third party resources clearly e.g. in the welcome message, splash screen (if any) or under the 'about' menu. If you are open about reuse, you are less likely to get into trouble if you unintentionally reused something copyrighted.
- You do not violate the license under which the work has been released. Please do not use 3rd-party images/audio in your software unless they have been specifically released to be used freely. Just because you found it in the Internet does not mean it is free for reuse.
- Always get permission from us before you reuse third-party libraries. Please post your 'request to use 3rd party library' in our forum. That way, the whole class get to see what libraries are being used by others.
Giving credit for reused work
Given below are how to give credit for things you reuse from elsewhere. These requirements are specific to this module i.e., not applicable outside the module (outside the module you should follow the rules specified by your employer and the license of the reused work)
If you used a third party library:
- Mention in the
README.adoc(under the Acknowledgements section) - mention in the
Project Portfolio Page if the library has a significant relevance to the features you implemented
If you reused code snippets found on the Internet e.g. from StackOverflow answers or
referred code in another software or
referred project code by current/past student:
- If you read the code to understand the approach and implemented it yourself, mention it as a comment
Example://Solution below adapted from https://stackoverflow.com/a/16252290 {Your implmentation of the reused solution here ...} - If you copy-pasted a non-trivial code block (possibly with minor modifications renaming, layout changes, changes to comments, etc.), also mark the code block as reused code (using
@@authortags
Format://@@author {yourGithubUsername}-reused //{Info about the source...} {Reused code (possibly with minor modifications) here ...} //@@authorpersons = getList() //@@author johndoe-reused //Reused from https://stackoverflow.com/a/34646172 with minor modifications Collections.sort(persons, new Comparator<CustomData>() { @Override public int compare(CustomData lhs, CustomData rhs) { return lhs.customInt > rhs.customInt ? -1 : (lhs.customInt < rhs.customInt) ? 1 : 0; } }); //@@author return persons;
Adding @@author tags indicate authorship
-
Mark your code with a
//@@author {yourGithubUsername}. Note the double@.
The//@@authortag should indicates the beginning of the code you wrote. The code up to the next//@@authortag or the end of the file (whichever comes first) will be considered as was written by that author. Here is a sample code file://@@author johndoe method 1 ... method 2 ... //@@author sarahkhoo method 3 ... //@@author johndoe method 4 ... -
If you don't know who wrote the code segment below yours, you may put an empty
//@@author(i.e. no GitHub username) to indicate the end of the code segment you wrote. The author of code below yours can add the GitHub username to the empty tag later. Here is a sample code with an emptyauthortag:method 0 ... //@@author johndoe method 1 ... method 2 ... //@@author method 3 ... method 4 ... -
The author tag syntax varies based on file type e.g. for java, css, fxml. Use the corresponding comment syntax for non-Java files.
Here is an example code from an xml/fxml file.<!-- @@author sereneWong --> <textbox> <label>...</label> <input>...</input> </textbox> ... -
Do not put the
//@@authorinside java header comments.
👎/** * Returns true if ... * @@author johndoe */👍
//@@author johndoe /** * Returns true if ... */
What to and what not to annotate
-
Annotate both functional and test code There is no need to annotate documentation files.
-
Annotate only significant size code blocks that can be reviewed on its own e.g., a class, a sequence of methods, a method.
Claiming credit for code blocks smaller than a method is discouraged but allowed. If you do, do it sparingly and only claim meaningful blocks of code such as a block of statements, a loop, or an if-else statement.- If an enhancement required you to do tiny changes in many places, there is no need to annotate all those tiny changes; you can describe those changes in the Project Portfolio page instead.
- If a code block was touched by more than one person, either let the person who wrote most of it (e.g. more than 80%) take credit for the entire block, or leave it as 'unclaimed' (i.e., no author tags).
- Related to the above point, if you claim a code block as your own, more than 80% of the code in that block should have been written by yourself. For example, no more than 20% of it can be code you reused from somewhere.
- 💡 GitHub has a blame feature and a history feature that can help you determine who wrote a piece of code.
-
Do not try to boost the quantity of your contribution using unethical means such as duplicating the same code in multiple places. In particular, do not copy-paste test cases to create redundant tests. Even repetitive code blocks within test methods should be extracted out as utility methods to reduce code duplication. Individual members are responsible for making sure code attributed to them are correct. If you notice a team member claiming credit for code that he/she did not write or use other questionable tactics, you can email us (after the final submission) to let us know.
-
If you wrote a significant amount of code that was not used in the final product,
- Create a folder called
{project root}/unused - Move unused files (or copies of files containing unused code) to that folder
- use
//@@author {yourGithubUsername}-unusedto mark unused code in those files (note the suffixunused) e.g.
//@@author johndoe-unused method 1 ... method 2 ...Please put a comment in the code to explain why it was not used.
- Create a folder called
-
If you reused code from elsewhere, mark such code as
//@@author {yourGithubUsername}-reused(note the suffixreused) e.g.//@@author johndoe-reused method 1 ... method 2 ... -
You can use empty
@@authortags to mark code as not yours when RepoSense attribute the to you incorrectly.-
Code generated by the IDE/framework, should not be annotated as your own.
-
Code you modified in minor ways e.g. adding a parameter. These should not be claimed as yours but you can mention these additional contributions in the Project Portfolio page if you want to claim credit for them.
-
At the end of the project each student is required to submit a Project Portfolio Page.
-
Objective:
- For you to use (e.g. in your resume) as a well-documented data point of your SE experience
- For us to use as a data point to evaluate your,
- contributions to the project
- your documentation skills
-
Sections to include:
-
Overview: A short overview of your product to provide some context to the reader.
-
Summary of Contributions:
- Code contributed: Give a link to your code on Project Code Dashboard, which should be
https://nus-cs2103-ay1819s2.github.io/cs2103-dashboard/#=undefined&search=githbub_username_in_lower_case(replacegithbub_username_in_lower_casewith your actual username in lower case e.g.,johndoe). This link is also available in the Project List Page -- linked to the icon under your photo. - Features implemented: A summary of the features you implemented. If you implemented multiple features, you are recommended to indicate which one is the biggest feature.
- Other contributions:
- Contributions to project management e.g., setting up project tools, managing releases, managing issue tracker etc.
- Evidence of helping others e.g. responses you posted in our forum, bugs you reported in other team's products,
- Evidence of technical leadership e.g. sharing useful information in the forum
- Code contributed: Give a link to your code on Project Code Dashboard, which should be
-
Contributions to the User Guide: Reproduce the parts in the User Guide that you wrote. This can include features you implemented as well as features you propose to implement.
The purpose of allowing you to include proposed features is to provide you more flexibility to show your documentation skills. e.g. you can bring in a proposed feature just to give you an opportunity to use a UML diagram type not used by the actual features. -
Contributions to the Developer Guide: Reproduce the parts in the Developer Guide that you wrote. Ensure there is enough content to evaluate your technical documentation skills and UML modelling skills. You can include descriptions of your design/implementations, possible alternatives, pros and cons of alternatives, etc.
-
If you plan to use the PPP in your Resume, you can also include your SE work outside of the module (will not be graded)
-
-
Format:
-
File name:
docs/team/githbub_username_in_lower_case.adoce.g.,docs/team/johndoe.adoc -
Follow the example in the AddressBook-Level4
-
💡 You can use the Asciidoc's
includefeature to include sections from the developer guide or the user guide in your PPP. Follow the example in the sample. -
It is assumed that all contents in the PPP were written primarily by you. If any section is written by someone else e.g. someone else wrote described the feature in the User Guide but you implemented the feature, clearly state that the section was written by someone else (e.g.
Start of Extract [from: User Guide] written by Jane Doe). Reason: Your writing skills will be evaluated based on the PPP
-
-
Page limit:
Content Limit Overview + Summary of contributions 0.5-1 (soft limit) Contributions to the User Guide 1-3 (soft limit) Contributions to the Developer Guide 3-6 (soft limit) Total 5-10 (strict) - The page limits given above are after converting to PDF format. The actual amount of content you require is actually less than what these numbers suggest because the HTML → PDF conversion adds a lot of spacing around content.
- Reason for page limit: These submissions are peer-graded (in the PE) which needs to be done in a limited time span.
If you have more content than the limit given above, you can give a representative samples of UG and DG that showcase your documentation skills. Those samples should be understandable on their own. For the parts left-out, you can give an abbreviated version and refer the reader to the full UG/DG for more details.
It's similar to giving extra details as appendices; the reader will look at the UG/DG if the PPP is not enough to make a judgment. For example, when judging documentation quality, if the part in the PPP is not well-written, there is no point reading the rest in the main UG/DG. That's why you need to put the most representative part of your writings in the PPP and still give an abbreviated version of the rest in the PPP itself. Even when judging the quantity of work, the reader should be able to get a good sense of the quantity by combining what is quoted in the PPP and your abbreviated description of the missing part. There is no guarantee that the evaluator will read the full document.
Follow the
- Get team members to review PRs. A workflow without PR reviews is a risky workflow.
- Do not merge PRs failing
CI . After setting up Travis, the CI status of a PR is reported at the bottom of the PR page. The screenshot below shows the status of a PR that is passing all CI checks.
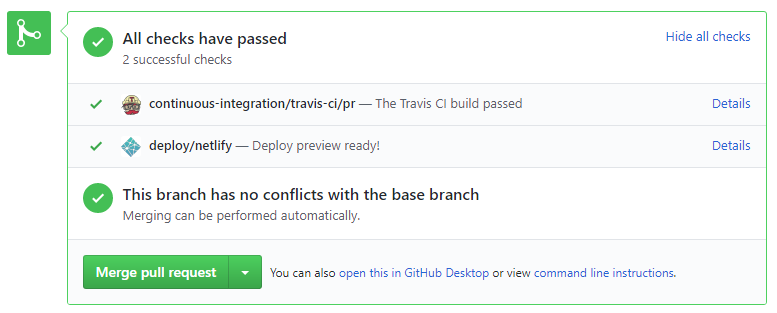
If there is a failure, you can click on theDetailslink in corresponding line to find out more about the failure. Once you figure out the cause of the failure, push the a fix to the PR. - After setting up Netlify, you can use Netlify PR Preview to preview changes to documentation files, if the PR contains updates to documentation. To see the preview, click on the
Detailslink in front of the Netlify status reported (refer screenshot above).
After completing v1.1, you can adjust process rigor to suit your team's pace, as explained below.
-
Reduce automated tests have benefits, but they can be a pain to write/maintain; GUI tests are especially hard to maintain because their behavior can sometimes depend on things such as the OS, resolution etc.
It is OK to get rid of some of the troublesome tests and rely more on manual testing instead. The less automated tests you have, the higher the risk of regressions; but it may be an acceptable trade-off under the circumstances if tests are slowing you down too much.
There is no direct penalty for removing GUI tests. Also noteour expectation on test code . -
Reduce automated checks: You can also reduce the rigor of checkstyle checks to expedite PR processing.
-
Switch to a lighter workflow: While forking workflow is the safest, it is also rather heavy. You an switch to a simpler workflow if the forking workflow is slowing you down. Refer the textbook to find more about alternative workflows: branching workflow, centralized workflow. However, we still recommend that you use PR reviews, at least for PRs affecting others' features.
You can also increase the rigor/safety of your workflow in the following ways:
- Use GitHub's Protected Branches feature to protect your
masterbranch against rogue PRs.
- There is no requirement for a minimum coverage level. Note that in a production environment you are often required to have at least 90% of the code covered by tests. In this project, it can be less. The less coverage you have, the higher the risk of regression bugs, which will cost marks if not fixed before the final submission.
- You must write some tests so that we can evaluate your ability to write tests.
- How much of each type of testing should you do? We expect you to decide. You learned different types of testing and what they try to achieve. Based on that, you should decide how much of each type is required. Similarly, you can decide to what extent you want to automate tests, depending on the benefits and the effort required.
Project Management → Revision Control →
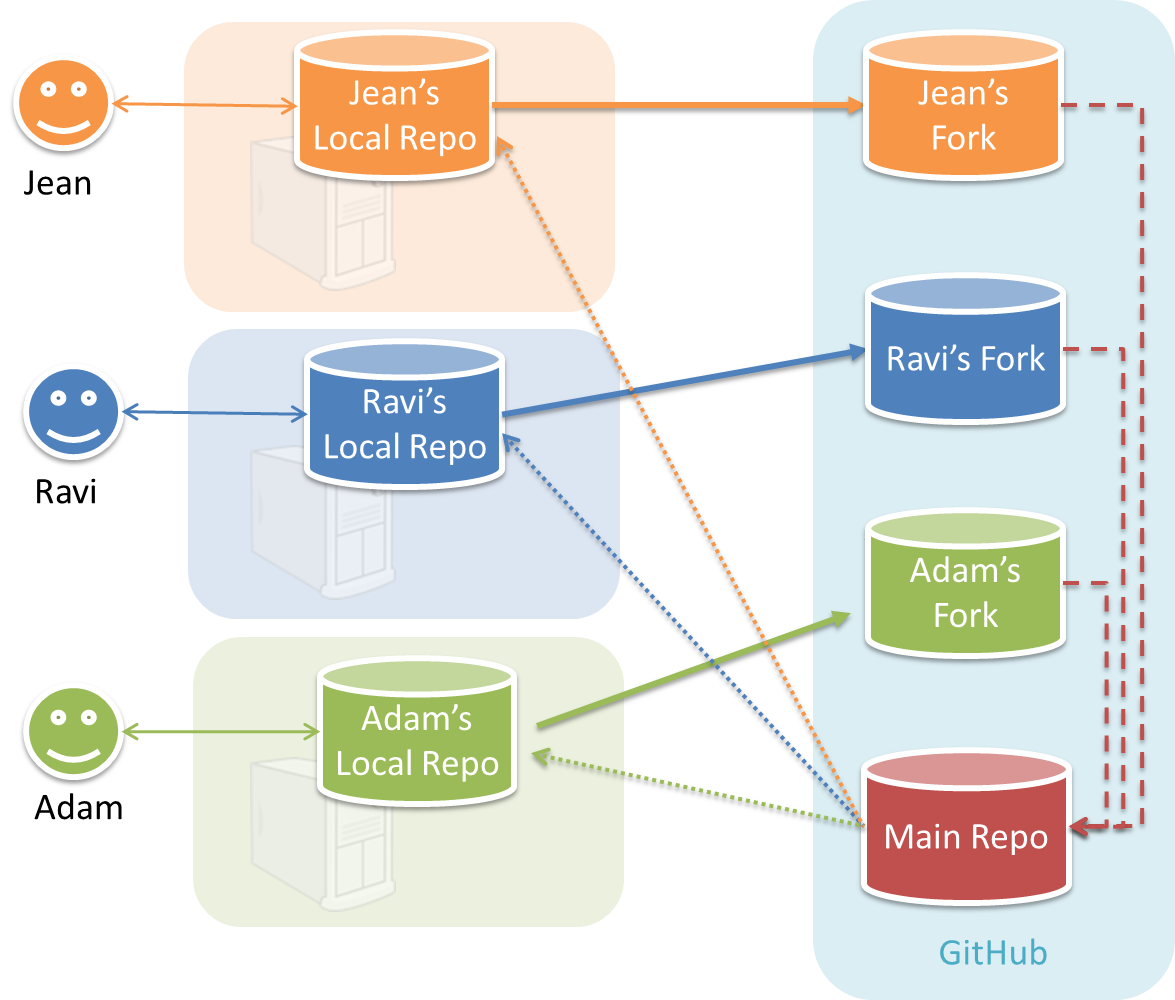
In the forking workflow, the 'official' version of the software is kept in a remote repo designated as the 'main repo'. All team members fork the main repo create pull requests from their fork to the main repo.
To illustrate how the workflow goes, let’s assume Jean wants to fix a bug in the code. Here are the steps:
- Jean creates a separate branch in her local repo and fixes the bug in that branch.
- Jean pushes the branch to her fork.
- Jean creates a pull request from that branch in her fork to the main repo.
- Other members review Jean’s pull request.
- If reviewers suggested any changes, Jean updates the PR accordingly.
- When reviewers are satisfied with the PR, one of the members (usually the team lead or a designated 'maintainer' of the main repo) merges the PR, which brings Jean’s code to the main repo.
- Other members, realizing there is new code in the upstream repo, sync their forks with the new upstream repo (i.e. the main repo). This is done by pulling the new code to their own local repo and pushing the updated code to their own fork.
- A detailed explanation of the Forking Workflow - From Atlassian
Documentation:
Recommended procedure for updating docs:
- Divide among yourselves who will update which parts of the document(s).
- Update the team repo by following the workflow mentioned above.
Update the following pages in your project repo:
- About Us page:
This page is used for module admin purposes. Please follow the format closely or else our scripts will not be able to give credit for your work.
- Replace info of SE-EDU developers with info of your team, including a suitable photo as described
here . - Including the name/photo of the supervisor/lecturer is optional.
- The photo of a team member should be
doc/images/githbub_username_in_lower_case.pnge.g.docs/images/damithc.png. If you photo is in jpg format, name the file as.pnganyway. - Indicate the different roles played and responsibilities held by each team member. You can reassign these
roles and responsibilities (as explained in Admin Project Scope) later in the project, if necessary.
- Replace info of SE-EDU developers with info of your team, including a suitable photo as described
-
The purpose of the profile photo is for the teaching team to identify you. Therefore, you should choose a recent individual photo showing your face clearly (i.e., not too small) -- somewhat similar to a passport photo. Some examples can be seen in the 'Teaching team' page. Given below are some examples of good and bad profile photos.

-
If you are uncomfortable posting your photo due to security reasons, you can post a lower resolution image so that it is hard for someone to misuse that image for fraudulent purposes. If you are concerned about privacy, you can request permission to omit your photo from the page by writing to prof.
Roles indicate aspects you are in charge of and responsible for. E.g., if you are in charge of documentation, you are the person who should allocate which parts of the documentation is to be done by who, ensure the document is in right format, ensure consistency etc.
This is a non-exhaustive list; you may define additional roles.
- Team lead: Responsible for overall project coordination.
- Documentation (short for ‘in charge of documentation’): Responsible for the quality of various project documents.
- Testing: Ensures the testing of the project is done properly and on time.
- Code quality: Looks after code quality, ensures adherence to coding standards, etc.
- Deliverables and deadlines: Ensure project deliverables are done on time and in the right format.
- Integration: In charge of versioning of the code, maintaining the code repository, integrating various parts of the software to create a whole.
- Scheduling and tracking: In charge of defining, assigning, and tracking project tasks.
- [Tool ABC] expert: e.g. Intellij expert, Git expert, etc. Helps other team member with matters related to the specific tool.
- In charge of[Component XYZ]: e.g. In charge of
Model,UI,Storage, etc. If you are in charge of a component, you are expected to know that component well, and review changes done to that component in v1.3-v1.4.
Please make sure each of the important roles are assigned to one person in the team. It is OK to have a 'backup' for each role, but for each aspect there should be one person who is unequivocally the person responsible for it.
-
Contact Us Page: Update to match your product.
-
README.adoc page: Update it to match your project.
-
Add a UI mockup of your intended final product.
Note that the image of the UI should bedocs/images/Ui.pngso that it can be downloaded by our scripts. Limit the file to contain one screenshot/mockup only and ensure the new image is roughly the sameheight x widthproportions as the original one. Reason: when we compile these images from all teams into one page (example), yours should not look out of place. -
The original
README.adocfile (which doubles as the landing page of your project website) is written to read like the introduction to an SE learning/teaching resource. You should restructure this page to look like the home page of a real product (not a school project) targeting real users e.g. remove references to addressbook-level3, Learning Outcomes etc. mention target users, add a marketing blurb etc. On a related note, also removeLearning Outcomeslink and related pages. -
Update the link of the Travis build status badge (
 ) so that it reflects the build status of your team repo.
) so that it reflects the build status of your team repo.
For the other badges,- either set up the respective tool for your project (AB-4 Developer Guide has instructions on how to set up AppVeyor and Coveralls) and update the badges accordingly,
- or remove the badge.
-
Acknowledge the original source of the code i.e. AddressBook-Level4 project created by SE-EDU initiative at
https://github.com/se-edu/
-
-
User Guide: Start moving the content from your User Guide (draft created in previous weeks) into the User Guide page in your repository. If a feature is not implemented, mark it as 'Coming in v2.0' (example).
-
Developer Guide: Similar to the User Guide, start moving the content from your Developer Guide (draft created in previous weeks) into the Developer Guide page in your team repository.
Product:
-
Each member can attempt to do a
local-impact change to the code base.Objective: To familiarize yourself with at least one
components of the product.Description: Divide the components among yourselves. Each member can do some small enhancements to their component(s) to learn the code of that component. Some suggested enhancements are given in the AddressBook-Level4 developer guide.
Submission: Create PRs from your own fork to your team repo. Get it merged by following your team's workflow.
Questions to do during tutorial:
Explain in your own words the interactions illustrated by this Sequence Diagram:
Consider the code below:
class Person{
Tag tag;
String name;
Person(String personName, String tagName){
name = personName;
tag = new Tag(tagName);
}
}
class Tag{
Tag(String value){
//...
}
}
class PersonList{
void addPerson(Person p){
//...
}
}
Draw a sequence diagram to illustrate the object interactions that happen in the code snippet below:
PersonList personList = new PersonList();
while (hasRoom){
Person p = new Person("Adam", "friend");
personList.addPerson(p);
}
Policy on suggested length for submissions
We don't usually give a strict page limit for documents such as User Guide and the Developer Guide. You need to decide yourself how long the document should be based on the purpose and the intended audience. You can determine the level of details required based on the samples we provide.
Why very narrow project scope?
Defining your own unique project is more fun.
But, wider scope → more diverse projects → harder for us to go deep into your project. The collective know-how we (i.e., students and the teaching team) have built up about SE issues related to the project become shallow and stretched too thinly. It also affects fairness of grading.

That is why a strictly-defined project is more suitable for a first course in SE that focuses on nuts-and-bolts of SE. After learning those fundamentals, in higher level project modules you can focus more on the creative side of software projects without being dragged down by nuts-and-bolts SE issues (because you already know how to deal with them). However, we would like to allow some room for creativity too. That is why we let you build products that are slight variations of a given theme.
Also note: The freedom to do 'anything' is not a necessary condition for creativity. Do not mistake being different for being creative. In fact, the more constrained you are, the more you need creativity to stand out.
Why project requirements are so vague?

"You tell me exactly what to do - I do that - you pay me (in grades)" is a model for contract work, not for learning. Being able to survive in imprecise, uncertain, volatile problem contexts is precisely what we are trying to teach you.
For example, the best way to communicate something often depends on what is being communicated. That is why we don't specify the precise content for project documents. Instead, we aim to refine project documents iteratively. We believe the learning experience will be richer if we let you decide the best way to present your project information rather than just following our instructions blindly. For example, in real-life projects you are rarely told which diagrams to draw; that is a decision you have to make yourself.